列表去重
列表去重:
如果列表中存在多个数据,去除列表中重复的数据。
方式思路1:
遍历原列表中的数据,判断在新列表中是否存在,如果存在,不用管。如果不存在,则放入新的列表中。
遍历for循环实现:
遍历是否存在——可以使用in。存入数据——append()
方式思路2:
在python中还有一种数据类型(容器),称为是 集合(set)。
特点:
集合中不能有重复的数据(如果有重复的数据会自动去重)
可以使用集合的特点对列表去重:
1. 使用set()类型转换将列表转换为集合类型
2. 再使用list()类型将集合转换为列表
缺点:
不能保证数据在原列表中出现的顺序(一般来说,也不考虑这件事)

案例
# 定义一个包含重复元素的列表
my_list = [3, 2, 4, 1, 2, 3, 3, 2, 1, 2, 3, 1]
# 初始化一个空列表,用于存储去重后的元素
new_list = []
# 遍历原列表中的每个元素
for i in my_list:
# 如果当前元素不在新列表中
if i not in new_list:
# 将当前元素添加到新列表中
new_list.append(i)
# 打印去重后的新列表
print(new_list)函数基础
案例:
# 1.定义一个函数,my_sum,用于对两个数字进行求和计算
def my_sum():
# 定义第一个数字并赋值为10
num1 = 10
# 定义第二个数字并赋值为20
num2 = 20
# 将两个数字相加,并将结果存储在变量num中
num = num1 + num2
# 打印计算结果
print(num)
# 调用my_sum函数,执行求和计算并打印结果
my_sum()函数存在的问题:
这个函数只能对10和20进行求和
问题解决:
想要解决这个问题,可以使用函数参数来解决
函数参数:
在函数定义的时候,使用变量代替具体的数据值(进行占位),在函数调用的时候,传递具体的数据值。
好处:
让函数更加通用,能够解决一类问题
掌握理解 形参和实参的概念

函数的返回值
函数的返回值,就像是你在厨房里做了一道菜,最后端出来的那道菜。你做菜的过程就是函数执行的过程,而最后端出来的菜就是函数的返回值。
什么时候需要返回值呢? 当你在做菜的过程中,可能会用到一些调料或者中间步骤的结果,比如你切好的蔬菜、调好的酱汁。如果你后面还要用这些调料或者中间结果来做其他菜,那么你就需要把它们保存下来,或者“返回”给后续的步骤使用。
举个例子:
def 做菜():
蔬菜 = 切菜()
酱汁 = 调酱汁()
最后端出来的菜 = 炒菜(蔬菜, 酱汁)
return 最后端出来的菜在这个例子里,`做菜` 函数执行后,最后端出来的菜就是返回值。如果你在后续的代码中还要用到这道菜(比如把它端上桌),那么你就需要把这个菜作为返回值返回,这样后续的代码才能继续使用它。
所以,返回值就是函数执行后得到的结果,如果你在后续的代码中还要用到这个结果,那就需要把它返回出来。
print()——》none
input()——》键盘输入的内容
type()——》类型
len()——》数据的长度(元素的个数)在函数中想要将一个数据作为返回值 返回,需要使用return关键字(只能在函数中使用)
作用:
1. 将数据值作为返回值返回
2.函数代码执行遇到return,会结束函数的执行
案例
# 定义一个名为my_sum的函数,接收两个参数a和b
def my_sum(a, b):
# 计算a和b的和,并将结果存储在变量num中
num = a + b
# 下面的print语句被注释掉了,因为它只会打印结果一次,且不能在函数外部使用
# print(num)
# 使用return语句将求和的结果返回给调用者,这样结果可以在后续代码中被重复使用
return num # 返回计算的和
# return语句之后的代码不会被执行,因为return会结束函数的执行
print('我是 return 之后的代码, 我会执行吗---> 不会执行') # 这行代码不会执行
# 调用my_sum函数,并打印返回的结果
print(my_sum(1, 2)) # 直接打印函数的返回值
# 调用my_sum函数,并将返回的结果保存到变量result中
# 这样可以在后续代码中继续使用这个结果
result = my_sum(10, 20) # 将求和的结果保存到变量result中
# 打印保存的结果
print('使用:1,直接打印:', result)
# 使用保存的结果进行进一步的计算,并打印
print('使用2,直接打印:', result + 10) # 在保存的结果上加10后打印返回值的说明:
def 函数名(): # 返回值none
pass # 代码中没有return
def 函数名():
return # return后边没有数据,返回值none
def 函数名():
return xx # 返回值是xx
变量进阶【理解】
在这一部分,我们了解python底层是如何处理数据的
变量的引用【理解】
1. 在定义变量的时候 变量 = 数据值, Python 解释器会在内存中开辟两块空间
2. 变量和数据都有自己的空间
3. 日常简单理解, 将数据保存到变量的内存中, 本质是 将 数据的地址保存到变量对应的内存中
4. 变量中存储数据地址的行为 就是引用 (变量引用了数据的地址, 简单说就是变量中存储数据), 存储的地址称为 引用地址
5. 可以使用 id() 来获取变量中的引用地址(即数据的地址), 如果两个变量的 id() 获取的引用地址一样, 即代表着, 两个变量引用了同一个数据,是同一个数据
6. 只有 赋值运算符=, 可以改变变量的引用(等号左边数据的引用)
7. python 中数据的传递,都是传递的引用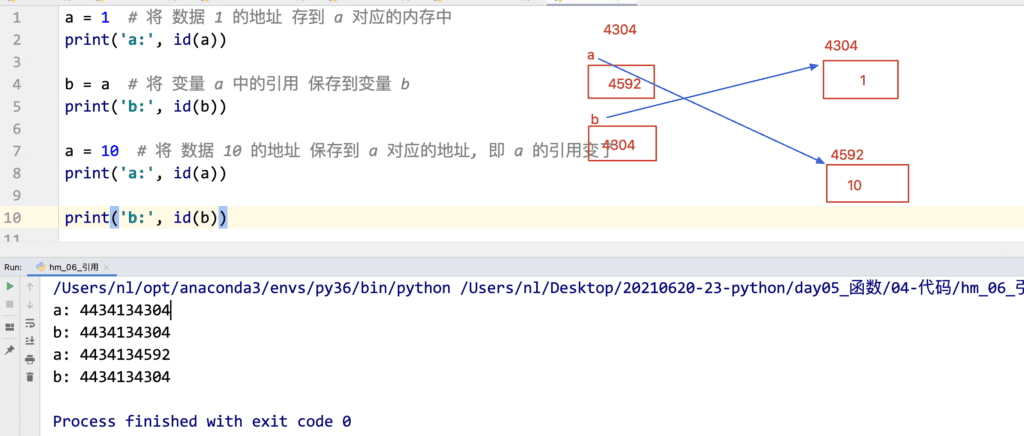
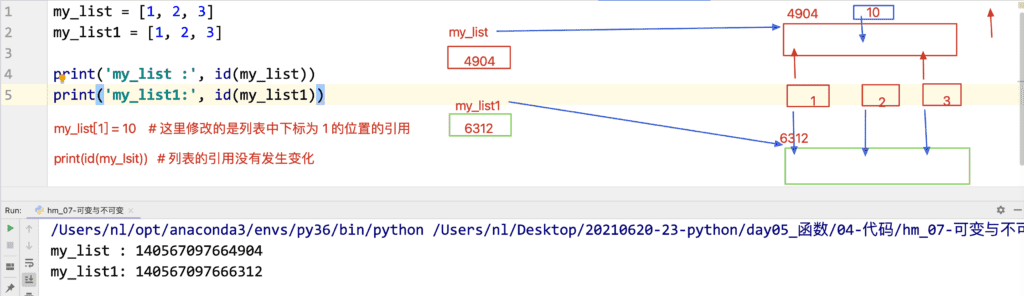
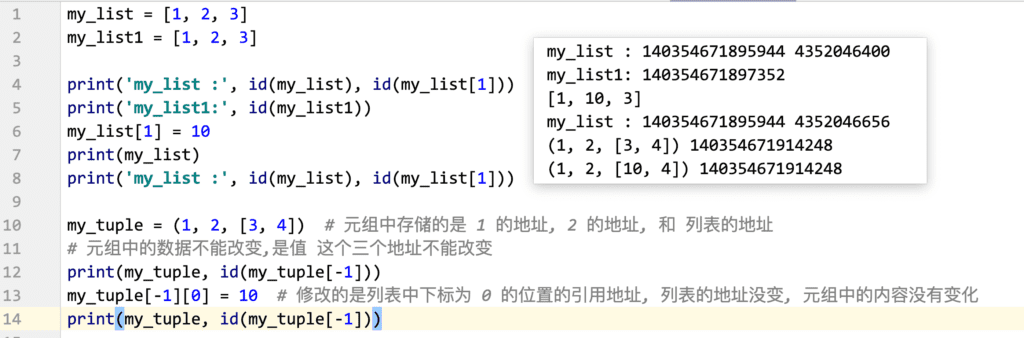
可变类型和不可变类型
数据类型:
int float bool str list tuple dict set
可变不可变指的是:
数据所在的内存是否允许修改,允许修改就是可变类型,不允许修改就是不可变类型(不使用 =,变量引用的数据中的内容是否会发生变化,会变化是可变的,不会变化是不可变的)
可变类型:
列表list、字典dict、集合set、列表.append()、字典.pop(键)
不可变类型:
int、float、bool、str、tuple
面试题1
def func(list1):
list1.append(10)
my_list = [1, 2]
func(my_list)
print(my_list)
① [1, 2] ② [1, 2, 10]
def func(list1):
list1[0] = 10
my_list = [1, 2]
func(my_list)
print(my_list)
① [1, 2] ②[10, 2]

面试题2
def func(list1):
list1 = [2, 1]
my_list = [1, 2]
func(my_list)
print(my_list)
① [1, 2] ②[2, 1]
- 只有 = ,可以改变变量引用
- 可变类型参数,在函数内部,如果不使用 = 直接修改形参的引用,对形参进行的数据修改会同步到实参中
面试题3
对于列表来说,+= 的本质是 extend (将一个可迭代对象的所有元素逐个添加到当前列表中。
)操作。
def func(list1):
list1 += [1, 2]
my_list = ['a', 'b']
func(my_list)
print(my_list) ===> ?
① ['a', 'b'] ② ['a', 'b', 1, 2]
面试题4
交换两个变量的值
a = 10
b = 20
# 方法1:常规方法,引入第三个变量
# c = a # 将变量 a 中的值先报=保存起来 10
# a = b # 将变量 b 中的值给 a
# b = c # 将变量 c 中的值(即最开始a的值)10 给 b
# print(a,b)
# 方法二:不适用第三个变量,使用数学中的方法
# a = a + b # a 的值 30
# b = a - b # 30 - 20 ===》10
# a = a - b # 30 - 10 ===》 20
# 方法三:重点掌握,python 特有
a,b = b,a
print(a,b)组包和拆包
组包(pack):
将多个数据值使用逗号连接,组成元组
拆包(unpack):
将容器中的数据值使用多个变量分别保存的过程,注意:变量的个数和容器中数据的个数要保持一致。
赋值运算符:
都是先执行等号右边的代码,执行的结果,保存到等号左边的变量中
案例
# 组包
a = 10 # 定义变量a并赋值为10
b = 20 # 定义变量b并赋值为20
c = b, a # 组包操作,将b和a的值组成一个元组赋给c
print(type(c), c) # 打印c的类型和值,输出:<class 'tuple'> (20, 10)
# 拆包
a, b = c # 拆包操作,将元组c中的值分别赋给a和b,此时a变为20,b变为10
print(a, b) # 打印a和b的值,输出:20 10
# 另一个拆包示例
x, y, z = [1, 2, 3] # 将列表[1, 2, 3]中的元素分别赋给x, y, z
print(x, y, z) # 打印x, y, z的值,输出:1 2 3局部变量和全局变量
变量:
根据变量的定义位置,可以将变量分为局部变量和全局变量
局部变量
局部变量:
在函数内部(函数的缩进中)定义的变量,称为局部变量。
特点:
1. 局部变量只能在当前函数内部使用,不能在其他函数和函数外部使用。
2. 在不同函数中,可以定义名字相同的局部变量,两者之间没有影响。
3. 生存周期(生命周期,作用范围)——》在哪 能用?在函数被调用的时候,局部变量被创建,函数调用结束,局部变量的值被销毁(删除),不能使用
所以函数中的局部变量的值,如果想要在函数外部使用,需要使用 return 关键字,将这个值进行返回
案例
# 定义一个名为func1的函数
def func1():
num = 10 # 在func1函数内部定义一个局部变量num,并赋值为10
print(f"func1 函数中 {num}") # 打印出func1函数中的num变量的值
# 定义另一个名为func2的函数
def func2():
num = 100 # 在func2函数内部定义一个局部变量num,并赋值为100
# 即使变量名相同,由于它们在不同的函数作用域内,因此它们是不同的变量
print(f"func2 函数中 {num}") # 打印出func2函数中的num变量的值
# 调用func1函数
func1() # 输出:func1 函数中 10
# 调用func2函数
func2() # 输出:func2 函数中 100
# 再次调用func1函数
func1() # 输出:func1 函数中 10全局变量
定义位置:
在函数外部定义的变量,称为 全局变量
特点:
1. 可以在任何函数中读取(获取)全局变量的值
2. 如何在函数中存在和全局变量名字相同的局部变量,在函数中使用的是 局部变狼的值(就近原则)
3. 在函数内部想要修改全局变量的引用(数据值),需要添加 global 关键字,对变量进行声明为全局变量
4. 生命周期:代码执行的时候被创建,代码执行结束,被销毁(删除)
案例
# 定义一个全局变量g_num并赋值为10
g_num = 10
# 定义函数func1
def func1():
# 尝试打印全局变量g_num的值,但是这里有一个错误,应该是func1中,而不是func2中
print(f"func1 中 {g_num}")
# 定义函数func2
def func2():
g_num = 20 # 在func2内部定义一个局部变量g_num,这个变量只在func2内部有效,不会影响全局变量g_num
print(f"func2 中 {g_num}") # 打印局部变量g_num的值,输出:func2 中 20
# 定义函数func3
def func3():
# global 只能在函数内部使用,在外部使用会报错
global g_num # 声明在func3中使用的g_num是全局变量,而不是创建一个新的局部变量
g_num = 30 # 修改全局变量g_num的值为30
print(f"func3 中 {g_num}") # 打印修改后的全局变量g_num的值,输出:func3 中 30
func1() # 调用func1函数,输出:func1 中 10
func2() # 调用func2函数,输出:func2 中 20
func3() # 调用func3函数,修改全局变量g_num的值,并打印它
print(g_num) # 打印全局变量g_num的最终值,输出:30,因为func3修改了它的值函数进阶
返回值-函数返回多个数据值:
函数中想要返回一个数据值,使用 return 关键字,如果将多个数据值组成容器进行返回,一般是元组(组包)
案例
# 定义一个名为calc的函数,接收两个参数a和b
def calc(a, b):
num = a + b # 计算a和b的和,并将结果赋值给变量num
num1 = a - b # 计算a和b的差,并将结果赋值给变量num1
return num, num1 # 返回一个包含两个结果(和与差)的元组
# 写法一:将calc函数的返回值赋给一个变量result
result = calc(10, 5) # 调用calc函数,传入10和5作为参数
print(result, result[0], result[1]) # 打印返回的元组,以及元组中的第一个和第二个元素
# 写法二:使用多重赋值直接将calc函数的返回值解包到两个变量x和y中
x, y = calc(20, 10) # 调用calc函数,传入20和10作为参数,并将返回的元组解包到x和y
print(x, y) # 打印变量x和y的值函数参数
形参的不同书写方法
函数传参的方式
- 形参
函数定义时声明的变量,用于接收传递的值。def greet(name): # 这里的 `name` 就是形参 print(f"Hello, {name}!") - 实参
函数调用时传递给函数的具体值或变量。greet("Alice") # 这里的 `"Alice"` 就是实参 - 形参、实参案例
def add(a, b): # `a` 和 `b` 是形参 return a + b result = add(3, 5) # `3` 和 `5` 是实参 print(result) # 输出: 8 - 位置传参
在函数调用的使用,按照形参的顺序,将实参值传递给形参# 定义一个名为func的函数,它接受三个参数a, b, c def func(a, b, c): # 打印出参数a, b, c的值,格式化字符串用于展示参数的值 print(f"a:{a},b:{b},c:{c}") # 位置传参:调用func函数时,根据参数的位置传递值 # 参数1对应a,参数2对应b,参数3对应c func(1, 2, 3) # 输出: a:1,b:2,c:3 - 关键字传参
在函数调用的时候,指定数据值给到那个形参# 定义一个名为func的函数,它接受三个参数a, b, c def func(a, b, c): # 打印出参数a, b, c的值,格式化字符串用于展示参数的值 print(f"a:{a},b:{b},c:{c}") # 关键字传参:调用func函数时,通过参数名来传递值 # 这样可以不按照参数定义的顺序传递值 func(a=2, b=3, c=1) # 输出: a:2,b:3,c:1 - 混合使用
1. 关键字传参必须写在位置传参的后面
2. 不要给一个形参传递多个数据值# 定义一个名为func的函数,它接受三个参数a, b, c def func(a, b, c): # 打印出参数a, b, c的值,格式化字符串用于展示参数的值 print(f"a:{a},b:{b},c:{c}") # 混合使用位置传参和关键字传参 # 可以在调用函数时混合使用位置传参和关键字传参 # 位置传参必须在关键字传参之前 func(1, 3, c=5) # 输出: a:1,b:3,c:5
案例
# 定义一个名为func的函数,它接受三个参数a, b, c
def func(a, b, c):
# 打印出参数a, b, c的值,格式化字符串用于展示参数的值
print(f"a:{a},b:{b},c:{c}")
# 位置传参:调用func函数时,根据参数的位置传递值
# 参数1对应a,参数2对应b,参数3对应c
func(1, 2, 3) # 输出: a:1,b:2,c:3
# 关键字传参:调用func函数时,通过参数名来传递值
# 这样可以不按照参数定义的顺序传递值
func(a=2, b=3, c=1) # 输出: a:2,b:3,c:1
# 混合使用位置传参和关键字传参
# 可以在调用函数时混合使用位置传参和关键字传参
# 位置传参必须在关键字传参之前
func(1, 3, c=5) # 输出: a:1,b:3,c:5缺省参数
缺省参数,又叫默认参数
列表.pop() # 不写参数,删除最后一个
列表.sort(reverse=True)
- 定义方式
在函数定义的时候,给形参一个默认的数据值,这个形参就变为缺省参数,注意:缺省参数的书写要放在普通参数的后边def greet(name, message="Hello"): # `message` 是缺省参数,默认值为 "Hello" print(f"{message}, {name}!") - 特点(好处)
缺省参数,在函数调用的时候,可以传递实参值,也可以不传递实参值。
如果传参,使用的就是传递的实参值,如果不传参,使用的就是默认值
案例
# 定义一个名为show_info的函数,它接受两个参数:name和sex
# sex参数有一个默认值'保密',这意味着如果在调用函数时没有提供sex的值,它将默认为'保密'
def show_info(name, sex='保密'):
# 打印出参数name和sex的值
print(name, sex)
# 调用show_info函数,只提供name参数的值,sex参数使用默认值'保密'
show_info('小王') # 输出: 小王 保密
# 调用show_info函数,同时提供name和sex参数的值
show_info('小王', '男') # 输出: 小王 男多值参数【可变参数/不定长参数】
print(1)
print(1,2)
print(1,2,3)
print(1,2,3,4)
当我们在书写函数的时候,不确定参数的具体个数时,可以使用 不定长参数
- 不定长位置参数(不定长元组参数)
1. 书写,在普通参数的前边,加上一个 * ,这个参数就变为不定长位置参数
2. 特点,这个形参可以接收任意多个 位置传参的数据
3. 数据类型,形参的类型是 元组
4. 注意,不定长位置参数 要写在普通参数的后边
5. 一般写法,不定长位置参数的名字为 args ,即(*args) # arguments 是 “arguments” 的缩写,表示“参数”。这是一种约定俗成的写法,目的是让代码更具可读性和一致性。 - 语法
# 定义不定长位置参数 def print_args(*args): # `*args` 表示接受任意数量的位置参数 print("Received arguments:", args) # 使用不定长位置参数 print_args(1, 2, 3) # 输出: Received arguments: (1, 2, 3) print_args("a", "b") # 输出: Received arguments: ('a', 'b') - 不定长关键字参数【不定长字典参数】
1. 书写,在普通参数的前面,加上两个 *,这个参数就变为不定长关键字参数
2. 特点,这个形参可以接收任意多个 关键字传参的数据
3. 数据类型,形参的类型是 字典
4. 注意,不定长关键字参数,要卸载所偶参数的最后边
5. 一般写法,不定长关键字参数的名字为 kwargs ,即(**kwargs),keyword arguments, - 语法
# 定义不定长关键字参数 def print_kwargs(**kwargs): # `**kwargs` 表示接受任意数量的关键字参数 print("收到的关键字参数:", kwargs) # 调用不定长关键字参数 print_kwargs(name="Alice", age=25) # 输出: 收到的关键字参数: {'name': 'Alice', 'age': 25} print_kwargs(city="New York", country="USA") # 输出: 收到的关键字参数: {'city': 'New York', 'country': 'USA'} - 完整的参数顺序
def 示例函数名(普通参数, 缺省参数1=10, *不定长位置参数, 关键字参数1, **不定长关键字参数): pass # 一般在使用的时候, 使用 1-2种, 按照这个顺序挑选书写即可 - 案例
# 定义一个名为func的函数,使用*args和**kwargs来接收可变数量的位置参数和关键字参数 def func(*args, **kwargs): # 打印args的类型和值,args是一个元组,包含了所有传递给函数的位置参数 print(type(args), args) # 打印kwargs的类型和值,kwargs是一个字典,包含了所有传递给函数的关键字参数 print(type(kwargs), kwargs) # 打印分隔线,用于区分每次函数调用的输出结果 print('-' * 30) # 调用func函数,不传递任何参数 func() # 输出args为(),kwargs为{},然后是分隔线 # 调用func函数,只传递位置参数 # 所有位置参数都被收集到args元组中 func(1, 2, 3) # 输出args为(1, 2, 3),kwargs为{},然后是分隔线 # 调用func函数,只传递关键字参数 # 所有关键字参数都被收集到kwargs字典中 func(a=1, b=2, c=3) # 输出args为(),kwargs为{'a': 1, 'b': 2, 'c': 3},然后是分隔线 # 调用func函数,同时传递位置参数和关键字参数 # 位置参数被收集到args元组中,关键字参数被收集到kwargs字典中 func(1, 2, 3, a=4, b=5, c=6) # 输出args为(1, 2, 3),kwargs为{'a': 4, 'b': 5, 'c': 6},然后是分隔线
print函数解析
print 是 Python 中用于输出内容到控制台的内置函数。它可以接受多个参数,并将它们打印到标准输出(通常是终端或命令行窗口)。以下是 print 函数的详细解析:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)参数说明
*objects:- 这是
print的主要参数,表示要打印的内容。 - 可以传递任意数量的参数(用逗号分隔),
print会将它们依次打印出来。 - 例如:
print(1, 2, 3)会输出1 2 3。
- 这是
sep:- 用于指定多个参数之间的分隔符,默认是一个空格
' '。 - 例如:
print(1, 2, 3, sep=',')会输出1,2,3。
- 用于指定多个参数之间的分隔符,默认是一个空格
end:- 用于指定打印结束时的字符,默认是换行符
'\n'。 - 例如:
print(1, 2, 3, end='!')会输出1 2 3!,并且不会换行。
- 用于指定打印结束时的字符,默认是换行符
file:- 用于指定输出的目标文件,默认是标准输出(
sys.stdout,即控制台)。 - 可以将其设置为一个文件对象,将内容写入文件。
- 例如:
with open('output.txt', 'w') as f: print('Hello, World!', file=f)
- 用于指定输出的目标文件,默认是标准输出(
flush:- 用于控制是否强制刷新输出缓冲区,默认是
False。 - 如果设置为
True,print会立即将内容写入目标文件或控制台,而不是等待缓冲区满。 - 例如:
print('Hello', flush=True)。
- 用于控制是否强制刷新输出缓冲区,默认是
函数的使用示例
- 基本语法
print('Hello, World!') # 输出: Hello, World! print(1, 2, 3) # 输出: 1 2 3 - 指定分隔符
print(1, 2, 3, sep=',') # 输出: 1,2,3 print(1, 2, 3, sep=' -> ') # 输出: 1 -> 2 -> 3 - 指定结束符
print('Hello', end=' ') # 输出: Hello (不换行) print('World') # 输出: World # 最终输出: Hello World - 输出到文件
with open('output.txt', 'w') as f: print('Hello, World!', file=f) # 将内容写入文件 output.txt - 强制刷新缓冲区
import time print('Loading', end='', flush=True) time.sleep(1) print('...', end='', flush=True) time.sleep(1) print('Done') # 输出: Loading...Done (逐步显示,而不是等待所有内容一起输出) - 格式化输出
name = 'Alice' age = 25 print(f'Name: {name}, Age: {age}') # 输出: Name: Alice, Age: 25
print 是 Python 中最常用的输出函数,具有以下特点:
- 支持多个参数,默认用空格分隔。
- 默认在输出后换行,但可以通过
end参数修改。 - 可以通过
sep参数自定义分隔符。 - 可以将输出重定向到文件或其他目标。
- 支持强制刷新输出缓冲区。